Our guest this episode was Eirini Schlosser, the founder and CEO of Dyania Health, an advanced healthcare AI research company that helps find clinical trials for patients with life impacting conditions. Eirini joined Reuben Hall to discuss the real-world uses, successes, and challenges of AI technologies in the healthcare setting.
“[We can use the] same [AI] technology, but save the hospitals millions of dollars where normally they would have to have a human being sitting there and completing a form and just doing manual chart review. Like even things as simple as sepsis reporting where you have the medical staff that might be reading a single EMR for an hour and a half just to be able to get the right conclusions and input for their reporting of the outcomes.” Eirini Schlosser on Dyania Health success story
Find Moving Digital Health on Apple Podcasts and Spotify, and subscribe to the MindSea newsletter to be notified about future episodes.
Takeaways
- Dyania Health uses AI to automate the chart review and abstraction process for clinical trials, saving time and improving efficiency.
- Synapsis AI, Dyania Health’s AI system, analyzes electronic medical records to identify patients who may be eligible for specific clinical trials.
- The match output from Synapsis AI provides a level of compatibility between patients and trials, helping physicians make informed decisions.
- Explainability is crucial in AI, and Dyania Health’s system provides granular explainability to physicians, allowing them to understand the reasoning behind the AI’s conclusions.
Chapters
00:00 Introduction and Background
03:00 Automating Chart Review and Abstraction
08:09 Matching Patients with Clinical Trials
12:16 Matching Output and Explainability
13:55 Synapsis AI vs. General Language Models
17:07 Feedback and Learning Over Time
21:52 The Problem of Inefficient Clinical Trials
25:47 Success Stories and Impact
29:43 Building the Dyania Health Team
38:09 Revolutionizing Clinical Trials
Read Transcript:
Reuben (00:05.435)
Welcome to the MindSea podcast series, Moving Digital Health. Our guest today is Eirini Schlosser. Eirini is the founder and CEO of Dyania Health, an advanced healthcare AI research company that helps find clinical trials for patients with life impacting conditions. Thank you for joining us today, Areeni.
Eirini Schlosser (00:26.562)
Thank you for having me, and nice to officially meet you. Looking forward to having a conversation and diving in around what we do.
Reuben (00:36.579)
Excellent. Maybe you could start with just giving us an overview of your background.
Eirini Schlosser (00:41.506)
Sure, absolutely. So, Eirini Schlosser, CEO, founder of Dyania. My background on paper has been what might seem to be a little bit all over the place geographically, but I’ll explain shortly how it ties together. So, I, over about 20 years ago, spent my summers digitizing my father’s patient records and grew up to be the only non-physician family a non-physician in my family. So effectively, the black sheep is a pharmacist in my family. And so decided just at the cusp of finishing in biochemistry that I did not want to go down the family path and accidentally fell into Morgan Stanley in investment banking where I spent a few years in London after going to business school there. I worked on mergers and acquisitions transactions that were focused on the healthcare technology and pharma space. And so had seen really the difficulty in making business decisions without a full view or complete view rather into data that would otherwise be available to help the medical fields make better decisions, both at the strategic and at the patient level.
And that was really where I started thinking about the problems around information being buried in free text and founded my first startup out of Morgan Stanley. Technically, it was moonlighting quite literally 2 a.m. to 4 a.m. until I left to do that full time about a decade ago. My first startup was focused on a type of tech AI called natural language processing.
And within, you know, AI has a little bit of an umbrella approach, but natural language processing is a type of AI that can understand free text and draw meaning and conclusions from anything that would be typed in free text. So effectively, you know, my first startup was focused in another industry, but some of my first investors. In 2018 had come to me and asked me to advise on the value of their electronic medical record data from a clinical research perspective and how it could help patients and bring drugs to market much quicker. I drove down the rabbit hole. Long story short is I founded Dianna Health in the end of 2019. We had our pre-seed capital funding in January of 2020 out of the gate with the entire focus of the company being on how we can automate the currently manual chart review and chart abstraction process that would normally require a human clinician to read, understand, and draw conclusions out of electronic medical records. Many use cases for this as a technology, but effectively, what we do is installed within the healthcare system’s firewall, so we’re not pooling any data outside of the healthcare system or hospital. And the purpose of it is to be AI as a service where we’re able to read and draw conclusions from EMRs automatically to notify the physicians when they have a patient that may benefit from a certain clinical study. And particularly the clinical studies are most often in oncology or very life threatening disease areas where the patients clinical characteristics must align with a certain order of events. So they must have finished one therapy, not yet started another, had their adverse events resolved, they finished the therapy over four weeks ago, and they had a surgical resection, et cetera, et cetera. And so there’s a very thin window of time when a patient’s characteristics must align, almost like stars aligning, where they could actually qualify for partaking in a clinical trial for therapies. And usually when they’ve exhausted all avenues for approved drugs, this is something that the patients really want. And in the normal circumstances, they’re just not found because by the time a human takes to read 30 minutes per EMR, it’s basically a fool’s errand to have teams of 20 people reading constantly, changing EMRs on a daily basis.
Eirini Schlosser (05:19.67)
We fill that exact gap and help the physicians get patients access to clinical trials in a better way. But the last kind of nice component is that we do not have access to the identities of the patients, nor do we want that. We reserve that for a conversation for the physician to have with their own patient.
Reuben (05:39.871)
And so how much faster is Dyania’s solution compared to the status quo of the manually extracting that data?
Eirini Schlosser (05:50.874)
Yep, absolutely. So, you know, 30 minutes per electronic medical record is pretty slow. Where we can get through EMRs in a matter of seconds. So it just depends on how far back we have to look. So how many characters are technically typed into the medical record. But the inference levels there are effectively seconds. So if you can get through 100,000 EMRs in a day.
We’re looking at a very different process. That being said, it does depend on the amount of computing power that the healthcare system has on premise. So I’m not sure if, you know, very few people are really familiar with the GPU market, but you know, Nvidia has basically had the highest monopoly and they’ve had backlog up until even next year of GPU, which is the type of computing power that would be necessary to run any AI models on. So the more GPU that we have, the faster it can get even into milliseconds.
Reuben (06:57.504)
But I guess that’s part of the trade-off of privacy versus the computer powers operating within the system of the EMR.
Eirini Schlosser (07:05.526)
Correct. But actually, even in the cloud, GPU is not currently very often available. So what we’ve seen is that typically the academic medical centers that will be already running research, they in many cases have some GPU that’s on-premise already available. And since they’re also the ones that are running clinical trials, it’s worked well for us. That being said, you know, we’re…
We are excited for the days when GPU available on cloud will become a reality again. But the lead times right now are months sometimes unless an institution has reserved it for a year at a time.
Reuben (07:44.863)
And maybe tell me a little bit more about the matching output. So, you know, as you’re, you know, reviewing all the electronic medical records, pulling out these insights, matching with patients, do you get like, you know, percentage match of, you know, this patient is 100% match for this trial or like, what does that look like?
Eirini Schlosser (08:09.454)
Absolutely. So within every trial, we’re usually starting off with around 30 to 40 clinical trial criteria. And each of those criteria may have embedded singular data types that they’re looking for. So for example, if we’re looking for metastatic castration resistant prostate cancer patients that are histologically confirmed, that could be one criteria in a clinical trial, but it’s actually five different conclusions or assertions that would be drawn by the AI and potentially more. So for example, if the physician had not typed whether the patient was castration resistant or not, we would then be comparing PSA levels and testosterone levels over time to deduce the castration resistance of that patient population. And so effectively…
This isn’t something that can be just plugged in and you get a percent match. We do a protocol scoping for every clinical trial that we’re working on where we break down the criteria into deterministic and objective queries that the AI can understand. So I’ll give you another example within cardiology. If it says, serious heart disease, we would be clarifying with the doctor. That we’re looking for patients who have a NEHA score of four or five, for example, and nothing below that. So anything that is any component of a clinical trial protocol that is subjective in a way that would be potentially misconstrued by even a human clinician is something that we have clarified upfront. And so the queries start out there as effectively finds that information in the history. So there’s an accuracy at first of the conclusions by our large language model being correct. So the fact that we found that a patient was given a type of biologic eight weeks ago, and we can understand the temporal assertion that’s tied to the fact that they were treated with a biologic.
And for what duration. And then the second aspect of that is assessing it against the criteria. And currently there’s no AI in the world that can effectively reason in the same way a human would. And so our system is physician driven for the reasoning engine to be able to have a logic that will then compare the outputs that the AI can give to against certain criteria and assess that. And so that’s more heuristic, if you will, or rule-based driven.
So basically where I’m getting at is there’s different performance scores overall, but once the accuracy score on a certain data type is established, then it’s assessed in a way that’s fairly black or white. And actually the black or white that we define is either it’s a match, not a match, borderline. And then it can also be that they’re not a match for that specific criteria because the information was not found. So, for example, if we’re looking for patients that have an FGFR1 mutation and they’ve never had a genetic panel done, the information, we can’t find what’s not in their history. So we can’t say that the patient deterministically does not have an FGFR1 mutation, but we also cannot say that the patient deterministically does. And so that would be what’s called a weak negative and what we would put comes out into the user interface as showing that the patient is not a match for that criteria because information was not found. And does that make sense? So basically you get kind of like a red light, yellow light, and green light for each criteria, whether the patients a match or not, and then you can see patients that are a match for all criteria individually.
Reuben (12:16.067)
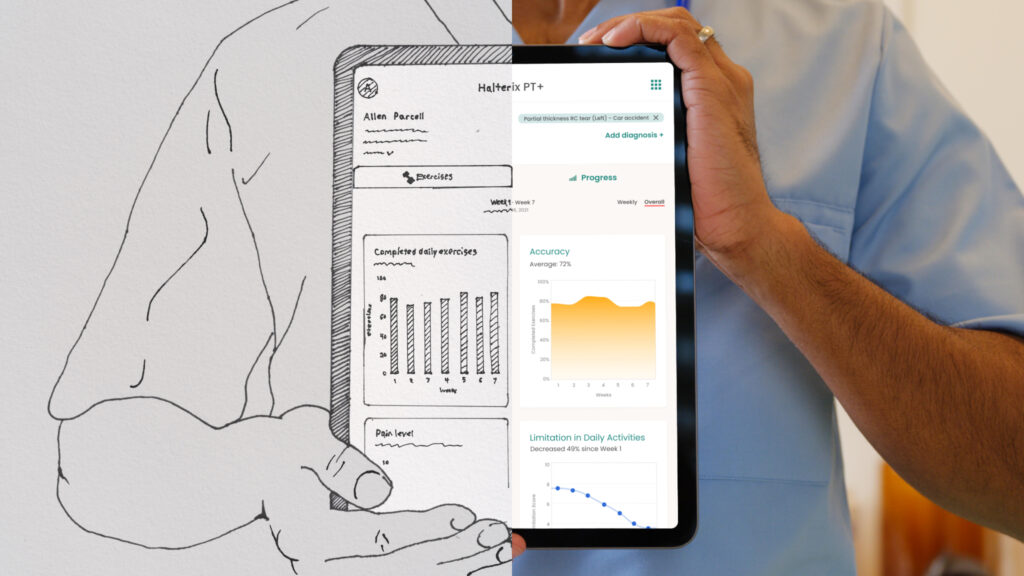
Yeah, that makes sense. I’m just trying to visualize what the doctor sees on their side. They might see a list of patients that have these different criteria, the red, yellow, green light. And if they go into the details of that patient, they see the parameters of why they fell in that category. And they can make their own judgment
Eirini Schlosser (12:40.494)
Exactly.
Reuben (12:45.297)
whether that is the right fit or not.
Eirini Schlosser (12:47.566)
Exactly. And one of the other benefits of our AI portion of the system is that it always draws on a justification. And so effectively we can pinpoint the part of the EMR and the part of the specific note that led Synapsis AI to derive the conclusion that it gave. And so the doctors have a granular level of explainability to be able to click in and demystify the black box, if you will. And so, you know, they… can test it in real time as they’re finding patient matches.
Reuben (13:21.755)
Yeah, I see that explainability aspect as being so important to the adoption on the physician side, because they want to know why it’s not just, you know, an answer. They want to know why that the AI came up with that answer. And that’s a critical component.
Eirini Schlosser (13:35.539)
Exactly.
Eirini Schlosser (13:40.938)
Absolutely.
Reuben (13:43.079)
So how in terms of the Synapsis AI, maybe talk about, you know, why it’s different than more of a general, you know, large language model that people may be, you know, familiar with. Yeah.
Eirini Schlosser (13:55.042)
Yeah, absolutely. So firstly, general models are what they’re called. They’re general. And so there’s a couple aspects of what we’ve been doing with our model that may get very task specific. So firstly, if you wanted a large language model to generate lifelike medical record notes, you would train it on EMR data.
And that’s one very good potential task that an LLM can perform because it can predict the next words or phrases that might be coming in the sentence and then save the position some time because it’s almost like a word prediction, if you will. Almost like when you’re typing on your iPhone and it suggests the next part of the phrase or word that you would type. That’s one task. If you wanted… you know, a physician to be able to make medical assessments and understand what’s in the medical note, you wouldn’t just feed it EMR data. So you would be training it on what we call is the pre-adaptation phase, which is effectively like taking the AI to medical school. And it’s being trained on everything from medical school textbooks, latest medical guidelines, or research often, especially in the cancer space, being updated on a very fast-paced basis. And so we actually retrain our model again and again on a quarterly basis, if not shorter time spans. So that’s one huge difference is that we’ve spent a significant amount of time training our models only on medical knowledge as a database.
Eirini Schlosser (15:48.062)
When we are doing our fine tuning, we have a full-time team of physicians that complete questions, answers, and justifications for the exact or similar tasks that the model would have to complete for a certain disease area within clinical studies. And so we compare the stage two of our training, which is the fine tuning to almost like taking it through a residency. And so if you think about how a human learns overall… everything has to be very task specific. If you were trying to train a model to answer USMLE board multiple choice questions correctly, that’s a very different task. And actually those models get a zero score on the tasks that we’re completing for clinical research. And so, I don’t wanna compare it to like a lawnmower trying to make coffee, but being very task specific in how you build and train an AI model and on what data particularly is quite important to the results that you get.
Reuben (16:51.423)
And then so is the decision from the clinician on whether a patient gets put into a trial or not, does that feedback and kind of improve the learning over time?
Eirini Schlosser (17:07.658)
So, it’s actually not whether the patient actually finally enrolls or not, because there might be some time lag of when we pre-screen them, let’s say, on October 2nd, and the patient doesn’t actually come in for a screening until mid-November, and their clinical characteristics may have changed. So, what we would view as a true positive versus a false positive is that when a human physician read through the EMR, based off of the information that was there, a true match would have actually matched all of those criteria data points. And so, you know, effectively, that’s the point where our technology and our performance really stops is when we’ve notified the physician that a patient matches. And from that point onward, it’s really up to the team to communicate with that patient, also, you know, help them understand what the trial is, why it will be beneficial for them or not be. Maybe it’s not a good trial for that particular patient because maybe they have trouble or maybe they have a comorbidity that prohibits them from being able to get to the hospital or the trial site center on a daily basis. And so there could be a myriad of reasons that a patient would not be necessarily a fit for a specific trial and it has to do with the regimen of the drug being that or the therapy that’s being administered.
However, we do have a tracking tool that allows the clinical research team within the hospital to be able to track where each patient is in that funneled process. So when they’ve come in, number one, whether they’re interested in this study or not, number two, whether they’ve passed screening that would actually have them enroll the same day and signed informed consents, et cetera. And so that’s a process that we give as a user interface that’s extra for the physicians to be able to track that and then re-identify their patients within Epic. We also are flexible on working, or Epic or whatever EMR system they’re working on. We’re also flexible on whether we can sync up within the EMR system or sync through something like the physician’s calendar, so that when they’re seeing patients on any given day and they’re looking at what their schedule is for the day, they can see a flag at that moment of which of those patients match trial criteria or not. And so there’s a few different flexible ways that we can work to fit within the habits of the principal investigators running studies, but it just depends on the involvement then from the IT departments at those hospitals.
Reuben (19:52.675)
And you mentioned a few different types of EMRs. Obviously, there’s the big ones like Epic and Cerner, but how many different EMRs have you integrated with so far?
Eirini Schlosser (20:05.59)
Yeah, so just to clarify, we don’t integrate into the EMR. What we’re, the only difference that the EMR choice makes at a specific healthcare system with how they work with us is that we try and make the lives of the IT departments a little bit easier, and we understand that they don’t have a lot of capacity, so our team actually drafts the SQL queries for them. And in order to draft the SQL queries, we just need what the access to the database schema. So that we can draft those SQL queries for them to have the data push. So it’s a one-time setup, and the clinically relevant data pushes into a sandboxed environment that’s within their computing system, their computing environment. So the overall, we work on free text, so we prefer that the data be in its raw form. And so the most Healthcare systems still in the US are storing everything on-premise in their own data centers. So the EMR systems themselves are not necessarily as relevant as it would be within other types of tools because we’re actually just getting it pushed directly from the data center in a read-only way.
Reuben (21:22.503)
Right, so you’re just integrating at a lower level, and that’s not so much of a concern. Got it. Outside of the technology aspect, which is fascinating to understand how everything works together, maybe talk about the problem Dyania Health is solving, and what are the consequences when clinical trials don’t find the right patients, and don’t find enough patients to run the trial?
Eirini Schlosser (21:52.546)
Yeah, absolutely. Well, firstly, 86% of studies are delayed from what they were originally planned to enroll at. But on top of that, about 30 to 40% are often terminated depending on the disease area. So when they’re terminated, effectively, the drug just doesn’t go to market, it stops its clinical trials, and then you’re looking at a pretty significant period of time before patients can get access. I mean, and when I say significant period of time, I mean, in some cases over a decade. And so, the drug might exist and be going through trials just for years and years on end because of the administrative delays of never finding patients to actually partake in the studies. Those patients might exist, but just for thin windows of time. And so not finding them at the right window when the stars align is just, it’s detrimental for the entire patient population in the future as well as for the current patients who could benefit from partaking in that study. That being said, more specifically in terms of what it costs and what the status quo looks like, a pharma company might come to market with a new drug going through clinical trials.
They’ll often have existing relationships with physicians who are running studies called principal investigators. And the process is very low tech. So effectively they’ll send the physician the protocol, which has all of the criteria listed and they’ll ask the physician, how many patients do you think that you will have that will meet these criteria? Physicians hand in the air, finger in the air says six. They have no database upon which to query that from. They only have their kind of guesstimated experience. And that six might be something that they’re committing to finding over eight months, 10 months, et cetera. And so these are really, really long periods of time, like when it is viewed as okay and acceptable in the industry for each hospital to be able to find 0.1 patient per month to be enrolled.
Eirini Schlosser (24:13.974)
Slow moving processes and particularly when you have disease areas that are much more prevalent like certain types of lung cancer or breast cancer where the patient populations do exist, it’s just no one’s finding them during that window. And so this is something where finding the needle in the haystack is where we come in terms of solving that problem. But as you can imagine, it’s a pretty crucial problem for the patients. And afterwards, even when the physicians are guessing that, they’re responsive after they, let’s say they get the enrollment allocation of six patients. Their next step is to have a team start doing manual chart review to find patients. They might use a more outdated version of natural language processing called named entity recognition based models, which are almost like an automated keyword search. So that often pulls up a pretty significant degree of errors. And effectively, even if they can do an initial filtering, then they just have their teams try and read as many thousands of EMRs as they can.
Ultimately, it ends up being a bit of a fool’s errand. And so the physician ends up just waiting for a patient to get referred to them and magically meeting the criteria on the day that they get referred to them. So it’s a pretty inefficient process at the moment. And that’s the exact component that we’re trying to solve.
Reuben (25:47.119)
Yeah, so it’s like you’re looking for 50 needles and 50 different haystacks across the… Yeah, and then everyone’s in their own silos. So the more that Synapsis AI is adopted in different institutions, the better or more efficient you’ll be able to be to find those very unique patients that are moving over time.
Reuben (26:16.243)
And do you have any success stories you can share about, you know, specific incidents where you were able to pull that together?
Eirini Schlosser (26:27.516)
Great question. So firstly, we are still under NDA with most of the trials that we’re working on.
Reuben (26:33.944)
Yeah, I understand. That’s why I say if you’re allowed to share them.
Eirini Schlosser (26:37.302)
Yeah, it’s hard to say. So well, what I can talk about is, we had first started where we were working first with the pharma companies. And historically, pre-pandemic years, pharma sponsors would assign a vendor to go to all of their trial sites who they had already contracted with. And I think the pandemic changed a lot because the healthcare systems were severely understaffed in their IT departments. And so the healthcare system started not really caring how much, you know, pharma was willing to sponsor in terms of the clinical research being done. It was more about the fact that they just didn’t have the capacity to do more technical integrations and deployments from an IT perspective. And so we listened carefully to the market and switched as per requests from the healthcare systems to focusing on a model that would deploy a healthcare system by healthcare system where we’re working, well, like our first and foremost client is the healthcare system or hospital. And as a result, it’s a one-time deployment for them that can then be utilized as the pre-screening tool for all of their clinical trials. So when you have large academic medical centers that are running, you know, a thousand to 2000 clinical trials per year,
This is highly valuable for them in terms of improving efficiency. Also to know otherwise, their alternatives when they don’t have a tool to do pre-screening is that they’re absorbing the costs of manual chart review and they’re also absorbing the costs when a study gets shut down and it’s no longer being sponsored by pharma. And so effectively they were excited to work with one vendor put everything they have into that one partner and then deploy from there. And so right now we are in several deployments with healthcare systems, almost all of which are, 80% are top 10 in the US on academic medical centers and focuses within cancer and cardiology at the moment. We are also doing a little bit in transplant and actually we’re disease diagnostic, but this has just been the requests from healthcare systems and where they see the need. So we’ll probably start to do more neurology and Alzheimer’s and other neurological conditions afterwards.
Reuben (29:14.899)
Excellent. Yeah, you’re in a resource constrained system and environment. That efficiency that AI can deliver to healthcare systems can make a huge impact, really. So that’s it’s amazing to hear that. I want to switch a little bit and talk about the team at Dyania. You know, it’s really hard to find top notch AI researchers and programmers, how did you build that team?
Eirini Schlosser (29:49.002)
Great question. Through many, many conversations and I’ve been in tech and specifically NLP for the past decade, but really it had to do with the fact that just starting from the founder’s perspective, I had taught myself how to code after I got out of investment banking and I did that because you can’t really manage an engineering process or guide product or any technology, especially a deep tech one without understanding the fundamentals behind it. And so, that was my first step about a decade ago, but I’ve been pretty deeply entrenched in the space since then. I had taken every course and what way I could get involved from an AI perspective in like 2016, 2017. And so, the first iteration of Dyania’s technology, I had actually built out with my team that we were working on with the future, with the previous startup. And so I think it definitely starts from the founder’s perspective and also the fact that we’re solving a problem that’s very mission driven. And so this isn’t trying to predict what watch a consumer would buy.
The number one, it’s something that can be very impactful for patients and overhauling an industry that has been quite honestly decades behind in terms of technological adoption versus other industries. And secondly, it’s a very challenging problem to have because medicine is not something that you can just, predict an outcome and not have interpretability, and that’s solved by having explainability of the AI and being able to justify it. But it’s a very complex moving target as an industry because of research that’s advancing. And so understanding medical notes and then assessing those conclusions with accuracy in the same way that a physician would is a very challenging problem. And so I think we attracted talent that was very excited by solving, by the opportunity to solve that type of problem, and also work in some of the top institutions. And so I think, you know, it’s been baby steps and baby steps. So every phase of the company’s journey has really been tied closely to the team that’s been behind it. So we’ve gotten, you know, scrappy when we had to. We have a subsidiary. We actually, during the pandemic, Greece was open and I’m half Greek, so I had kind of a foot in the door.
And physicians there had a gap of three to five years before starting their residencies after they graduated med school. And so we started recruiting full-time physicians to train the AI through the pandemic. And I think that for us was a blessing in disguise in terms of the timeframe we were given to just focus on the technology, because otherwise, I think the healthcare space is not really an industry that you can launch a minimum viable product and then test it out with the market. If you test it out and it doesn’t work, people remember you and you have one silver bullet in healthcare. I think physicians are not accustomed to using AI and if it doesn’t work the first time, you’re done. I think with that in mind, we’ve had a few perfect storms aspects come in at the same time of everything happening in the right way. But we’ve also been in the wrong timing. I mean, getting our pre-seed funding January 2020 was arguably at the time the wrong timing. And then next month, we had investors saying, so is Dyania going to be making toilet paper? What are we going to do? And so everything happens for a reason. But just going back to kind of the perfect storm opportunity that we had,
Eirini Schlosser (34:00.654)
If we look back between the lines, I was running a nonprofit within the context of the Greek economic crisis with partnerships with the US in 2009, 2010. And basically, we were helping students get scholarships and we were running professional mentorship programs. And many of those students were PhD students in engineering and medicine. Fast forward a decade and I had already built perfect network for this. So there is, because of the brain drain from a front that happened from Greece in, you know, in the Greek economic crisis, there ended up being a disproportionate amount of Greeks within these focus areas of engineering and medicine. And so that came together pretty perfectly in terms of what we were building with this. But, you know, it’s not an all Greek team by any means either.
Um, you know, it’s, uh, come together one step at a time, but we’ve made a really conscious effort to hire the best people that were right for specific roles. And sometimes it came through applications. Sometimes it came through us reaching out to profiles that we knew we needed with the right experience, um, you know, working with recruiters, it’s, it’s not easy to find the right people with exactly the right set of skills to bring to the table. And so I think, yeah, it does take funding as well. It’s not something that just comes out of the gate, but the earlier people get involved, the more exciting the journey ends up being.
Reuben (35:42.719)
Yeah, and it is similar to a lot of successful startups in terms of, you know, you need a little bit of luck to survive and make it through those early times, but also a brilliant team that is committed and passionate about the work we’re doing or the work you’re doing. So it sounds like you have both and are really making an impact, which is impressive.
Eirini Schlosser (36:10.146)
Thank you. Yeah, luck, I have to say it, you know, the ChatGPT announcement really did work in our favor because suddenly all potential clients understood what we were doing. And I think there’s been a lot of scar tissue in the industry because otherwise natural language processing, that’s been kind of the flag that’s been waved around for the past five years was really only like the NL, the name, identity recognition models that I mentioned before where that’s still being viewed as kind of cutting edge. C-TAKES was developed by Mayo Clinic and Apache in 2006 and it’s still used pretty consistently. And so, making sure that we were explaining to people that this is not a data mining operation and rather we are AI as a service got a lot easier when they could actually visualize what AI as a service meant and that we weren’t just trying to pull data out from their firewalls, because I think there’s been a lot of scar tissue, as well as bodies in the graveyard around companies just trying to just extract data, data from the healthcare systems, and they just had clammed up and didn’t want to work with anyone. So I think the luck of, we were already working on LLMs. We had our own GPU. We acquired it at the last minute before Elon Musk announced clearing out the market with his $300 million investment in GPU, and suddenly no one can get their hands on GPU. So we’ve had a few right places at the right time or right decisions at the right time moments, and I think that got us where we are today. But it’s definitely been an exciting road this year, so we’re even more excited for next year’s.
Reuben (37:56.447)
Cool, well that’s a perfect segue looking forward, like what’s the next step, what are some of the other ways that you’re looking to revolutionize clinical trials?
Eirini Schlosser (38:09.334)
Yep, absolutely. Well, you know what’s interesting is that when we’ve demoed for physicians, you know, how it works and they can see the under the hood engine of there’s a clinical note in front of them, you know, we can type any question about the clinical note and our synapsis AI gives an answer. They started thinking, well, if we’re asking you whether the patient’s disease progressed and the tumor size increased and it’s telling us yes, because the tumor increased from 0.5 centimeters to 1.5 centimeters, that would mean that you’re also deducing the tumor size. And we said, well, yeah, exactly. We just don’t even have to assess it against any criteria if we’re just looking for tumor size, but that’s what we’re deducing automatically. And they said, okay, great. Well, we have all these registries and reporting requirements where we have to submit for disease accrediting bodies, for the Joint Commission, quality control, population overview, and most of this information is coming from the notes. While you’re using the same technology to match patients for clinical trials, can you also just fill out this form in an automated manner? We said, yes. Same technology, but saves the hospitals millions of dollars where normally they would have to have a human being sitting there and completing a form and just doing manual chart review. Like even things as simple as like sepsis reporting where you have the medical staff that might be reading a single EMR for an hour and a half just to be able to get the right conclusions and input for their reporting of the outcomes. And so yeah, that’s been one way that we’ve been moving. Also, retrospective or prospective observational studies when the conclusions that are being drawn from the notes can be used to compare the outcomes of certain therapies. And so it would be effectively like an observational study versus a concurrent trial where a patient’s enrolling and partaking. But that’s quite important because it can prove out impacts of variations in gray areas when standard of care is not exactly clear or there’s not a clear path for a patient population that has undergone a specific set of events.
Reuben (40:42.111)
Excellent. Well, certainly looking forward to what comes next with Dyania Health, and thank you so much for joining on the podcast today, Irene.
Eirini Schlosser (40:52.75)
Thank you for having me.
Reuben (40:54.879)
And thanks for everyone else who is listening along to the Moving Digital Health podcast. If you enjoyed the conversation, please go to movingdigitalhealth.com to subscribe to the MindSea newsletter and be notified about future episodes.